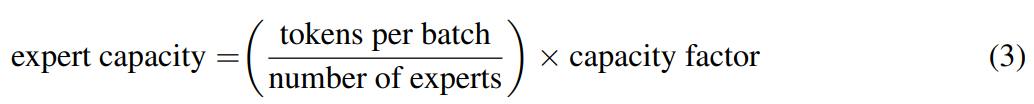- 爱妻自媒体-微信公众平台文章推荐
机械之心报道
[本文来自:www.ii77.com]
编纂:魔王、杜伟、张倩 [原创文章:www.ii77.com]
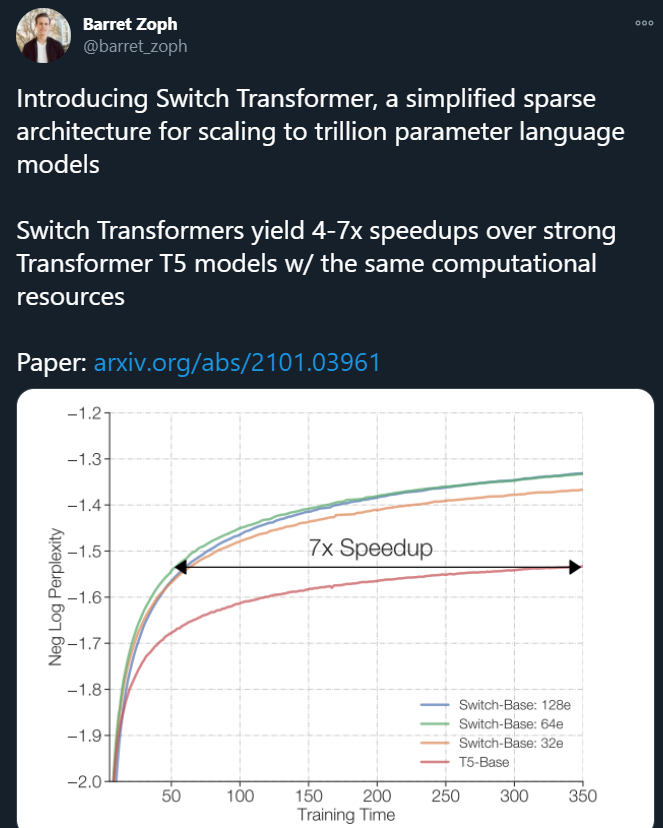
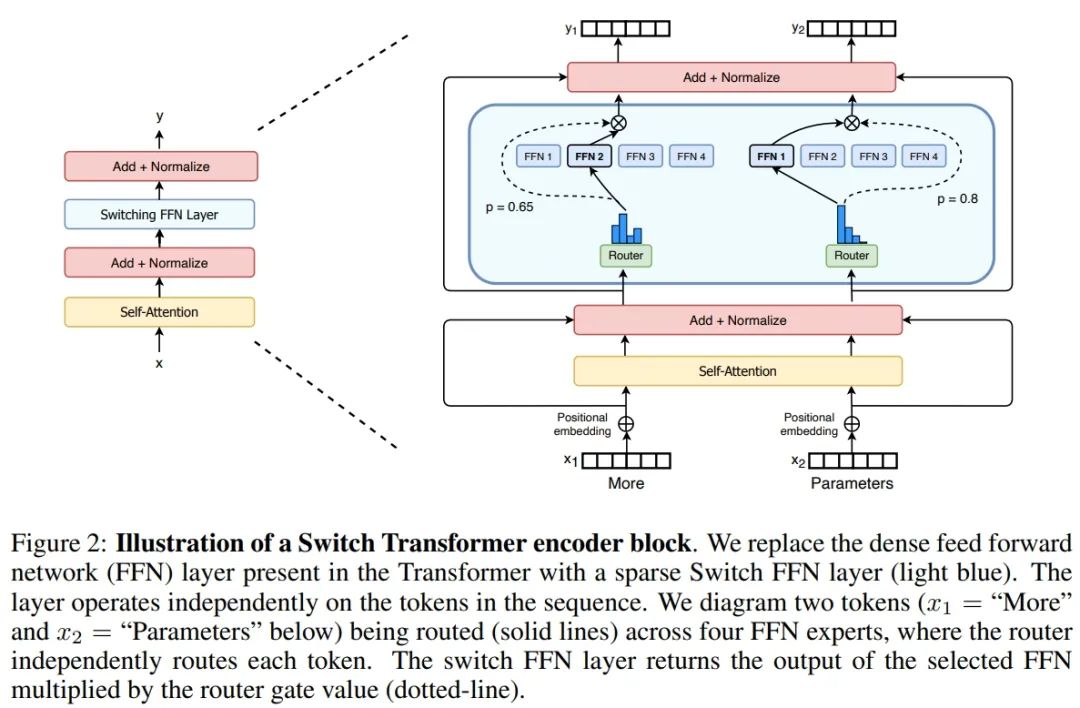
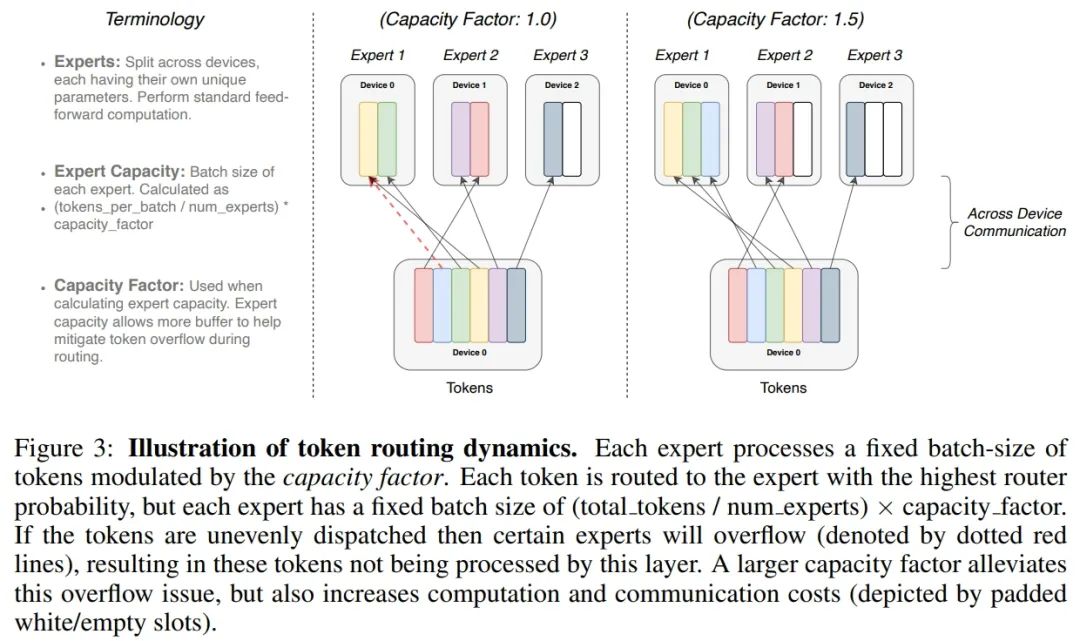
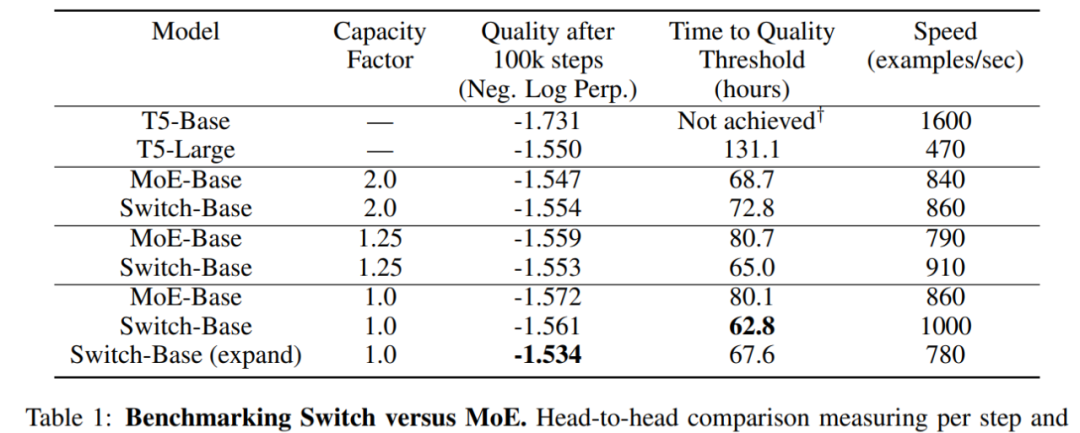
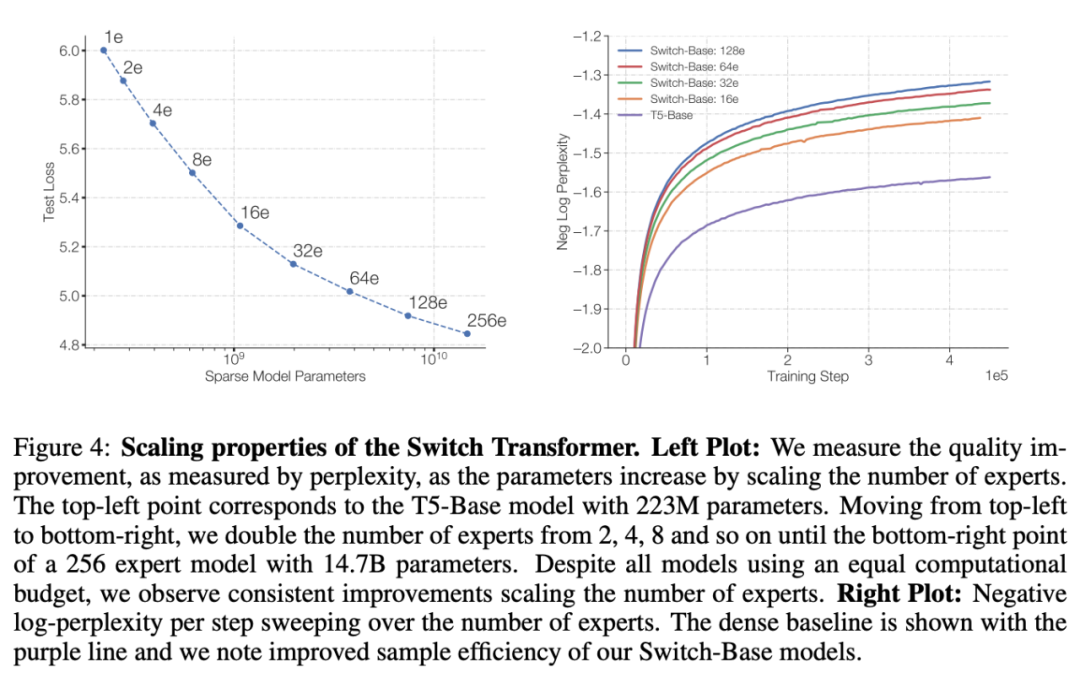
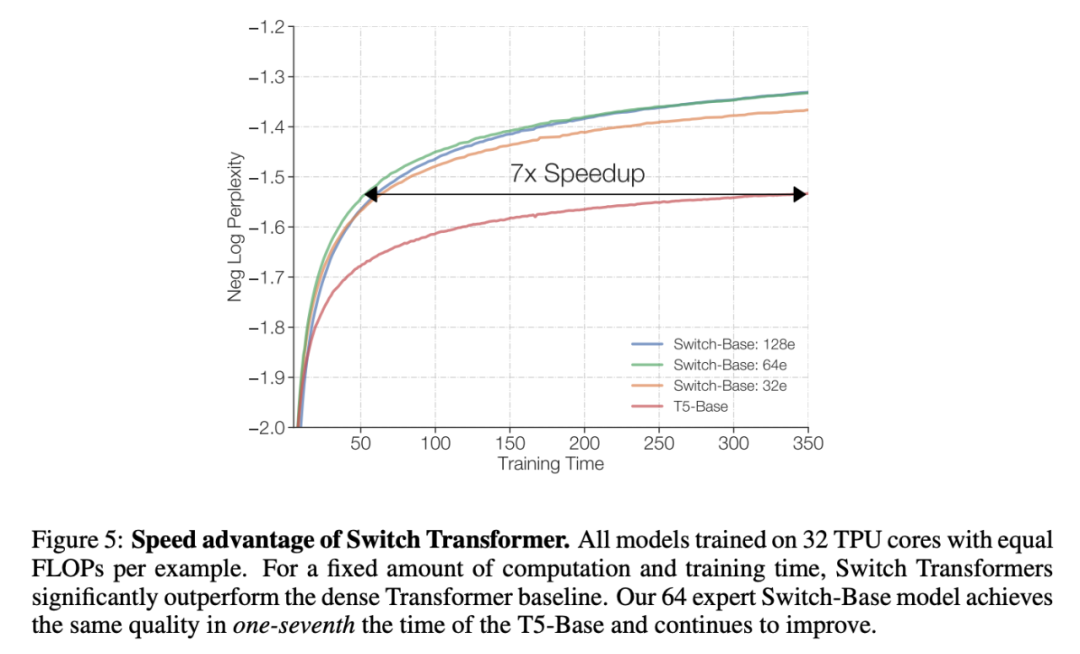
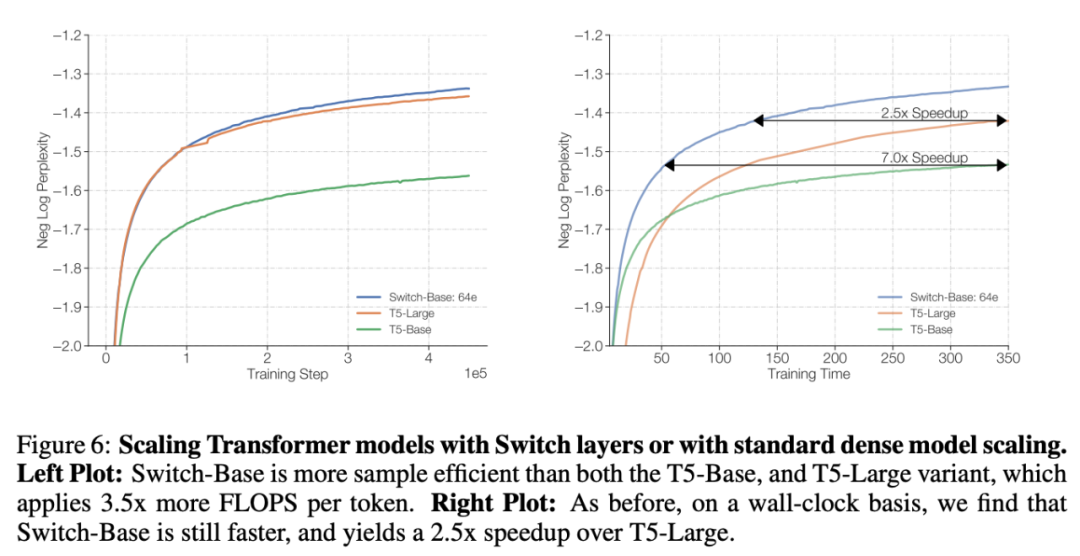
方才,Google Brain 高级研究科学家 Barret Zoph 发帖透露,他们设计了一个名叫「Switch Transformer」的简化稀少架构,能够将说话模型的参数量扩展至 1.6 万亿(GPT-3 是 1750 亿)。在较量资源沟通的情形下,Switch Transformer 的练习速度能够达到 T5 模型的 4-7 倍。
论文链接:https://arxiv.org/pdf/2101.03961.pdf
代码链接:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
对大型稀少模型使用可选择行精度(Selective precision with large sparse models)
为实现不乱性使用更小的参数初始化(Smaller parameter initialization for stability)
正则化大型稀少模型(Regularizing large sparse models)

© THE END
转载请关联本公家号获得授权
投稿或追求报道:content@jiqizhixin.com

点击上方“ 蓝色字体 ”,选择 “ 设为星标 ” 要害讯息,D1时间送达! 好多组织现在需要采用现代工作场合解决方案以连结领先地位。数字化转型不光对于IT部门至关主要,对于组织
「极客头条」—— 手艺人员的新闻圈! CSDN 的读者同伙们早上好哇,「极客头条」来啦,快来看今天都有哪些值得我们手艺人存眷的主要新闻吧。 整顿 | 丁恩华 出品 | CSDN(ID:CSDNne
阿迪达斯最新推出3D打印中底活动鞋,这款被称为4D Fusio的荧光色鞋子在Instagram上被球鞋黑幕炒作泄露。 这款新鞋具有精明的Primeknit鞋面,黑色,粉红色和橙色的编织物使鞋面变薄和变
2021年1月13日,我们在南极熊的“3D打印招投标”专栏发现,国内又发生了一个“激光选区熔化成形设备”大订单,3台打印尺寸达600mm以上的四激光金属3D打印机。其招标(编号0664-2040S
海信今天在CES 2021线上发布会上揭开了TriChroma激光电视新时代的面纱,这是一种最进步的显露手艺。这项新手艺将应用于多种设备,旨在在新的生态下从新保持人,天然和社会。 海信激
你好, 2021 你好,电信人 芳华须早为 岂能长少年 专心办事客户 细心看待工作 静心进修争优用心提拔自我 工作之余 以好书 感触文字浪漫 以画笔 勾勒世界绚烂 以照片 定格瞬间美妙
焦点概念 ➢ 软件!已经成为智能驾驶的焦点能力 一、软件在智能汽车的中的价格量将大幅提拔 二、软件厂商起头深度接入智能驾驶研发,甚至有望与整车厂直接合作 三、智能驾驶两
云原生分布式文件系统 JuiceFS 正式开源 1月11日,Juicedata 果汁数据科技官方账号公布 JuiceFS 正式开源,这是一个云原生分布式文件系统,经由了四年的持续迭代和累计几万万小时的线上
将 「雷科技Lite」收藏为我的小法式,不再错过出色内容 编纂 丨钟立磊 “上海白领体检非常率99%”,“90后的五大健康 困扰”等话题一再登上热搜;头秃、肥宅等与 健康问题相关的舆
自2010年以来,国度起头越来越正视半导体财富,并慢慢加大对于国内半导体财富的投入。2014年国度集成电路财富投资基金正式设立,首期总规模达1387亿元,随后吸引了多量的处所当局
本文内容来自网友供稿,如有信息侵犯了您的权益,请联系反馈核实
Copyright 2024.爱妻自媒体,让大家了解更多图文资讯!