- 爱妻自媒体-微信公众平台文章推荐
..在半导体财富尤其是处理器、SoC芯片等偏向似乎没有太多声音。从近几年..半导体财富成长来看,固然具体的产物并没有太多,不外但凡有新品显现,都以奇特的设计和规格让人面前一亮。NEC在2017年发布了一款全新的矢量处理器,并在2018年正式将其推向市场。和传统的通用处理器、GPU加快器比拟,矢量处理器还对照少见。今天,本文将和你一路解读NEC矢量处理器背后的机要。 [转载出处:www.ii77.com]
NEC在高机能处理器设计上拥有雄厚的经验,其绚烂的极点是在2002年摆布推出的Earth Simulator Computer也就是地球模拟器超等较量机,这款产物占有了全球最快超等较量机的宝座长达三年之久,而且大部门焦点处理器都由NEC设计完成,其特点就是进步的矢量较量设计。不外,因为其时的通俗用户对矢量较量需求不足,是以这类产物距离主流市场较远,NEC的矢量处理器往往只能用于大型设备,完全称不上公共化。
▲NEC在高机能处理器研究上具有雄厚的经验
事物在发生着转变。跟着AI较量的鼓起,矢量加快器又起头逐渐成为好多用户的选择。鉴于此,NEC又起头从新考虑将矢量较量相关产物推向主流市场。2017年,NEC公布推出全新的矢量超等较量机SX-Aurora TSUBAME,个中的较量焦点Vector Engine超等矢量卡(下文简称为“VE卡”)一经发布就引起了世人存眷。
这款采用主流PCIe接口设计、专攻矢量较量的产物使用局限极其普遍,NEC称其可以支撑“尺度情况”,也就是支撑Linux和英特尔x86架构。考虑到NEC在之前矢量处理器设计上的保守,这不得不说是一次重大改变。
有何优势?浅析矢量处理器的优势
对历久存眷本刊的读者来说,矢量和标量的概念应该不生疏。所谓矢量,又可称为向量,就是指具有偏向和巨细、且知足平行四边形轨则的几许对象。标量则只有巨细,没有偏向。一样来说,矢量多用在工程学、物理学中,好比位移、加快度、力矩、电流密度等都需要用矢量来透露。值得注重的是,矢量在代数中能够用矩阵的体式透露。好比矢量a能够透露为a=[a, b, c],个中a,b,c离别是矢量在三维坐标系统中的坐标值。
因为矢量的数组特征使其能够一次性进行多组较量,是以从一起头矢量较量和相关矢量处理器就颇受正视。从20世纪70年月一向到20世纪90年月,矢量较量和相关矢量处理器都是超等较量机的焦点。随之鼓起的就是一些处理多重矢量的手艺,包罗MIMD多指令多数据、SIMD单指令多数据、VLIM超长指令集架构等。这些手艺都是进展经由削减指令的数量,经由大量数据进行并行较量,一次性处理更多的内容。
在这里,我们经由一个例子来显露CPU传统的“轮回”较量和矢量处理器在较量方面的差别。
从例子能够看出,CPU每次只能加一个数据,10个周期才能做完这件事情。然则对矢量处理器而言,行使规模优势,一次能够执行10次运算,一个周期就能做完10个较量。这是典型的单指令多数据流处理方式。比拟传统的CPU,在面临大量并行数据时,矢量处理器效率更高。
因为矢量处理器在大规模数据较量上的优势,是以任何现代较量架构都无法轻忽其存在。实际上,现代CPU往往都已经包含了矢量较量模块。好比英特尔和AMD很早就推出了MMX、SSE、3D Now!、AVX等指令集,经由特别的矢量加快模块和指令,可以大幅度加快相关矢量较量。
不外,CPU依旧有其在逻辑较量上的优势,矢量较量并不是它的重点,一样只有在IBM Power 9如许专为超等较量机和大型机设计的处理器中才专门设计了超大规模的矢量较量焦点。即使如斯,矢量较量也会给传统处理器带来极大的机能提拔。好比英特尔新近到场的AVX-512指令集就可以大幅度增强AI较量等这类自然的大数据量、并行度极高的矢量较量。
除了CPU之外,GPU则可被称为自然的矢量加快器。传统的图形较量的极点转换自己就是为矢量较量而生,再加上像素较量方面RGBA的固定模式,是以GPU的每一个较量焦点都能够被看做一个矢量加快单元。诸如英伟达最新的Volta、Turning等架构,更是能够算作是专为图形较量设计的矢量加快器。
除了CPU和GPU外,市场上还有专门的矢量加快处理器、矢量较量机等。这类产物在焦点架构上设计更为简练,并不包含太多的附加功能,也没有为特定用途优化,其目的就是经由纯粹的矢量较量焦点设计,为AI较量、特别并行较量、超等较量机等供应加快较量的能力。
本期的主角VE超等矢量卡以及其焦点SX-Aurora处理器恰是这种“纯粹”的产物,专为加快而生,别无旁骛。术业有专攻,专业的加快处理器天然有必然的优势,在架构设计上也或者存在和传统通用加快器的差别,值得研究。
▲SX-Aurora TSUBAME超等较量机
从SX-Aurora TSUBAME超等较量机到VE超等矢量卡
要认识VE超等矢量卡,我们先来一路看看SX-Aurora TSUBAME超等较量机。这款超算是NEC对所谓“尺度情况”的首次测验,其特点就是采用了英特尔的处理器,支撑PCIe总线。凭据分歧的设置,在风冷情况下,SX-Aurora TSUBAME能够实现1颗或许2颗处理器,然则搭载1个、2个、4个甚至8个VE卡的分歧设置方案。在水冷情况下,SX-Aurora TSUBAME最多可以实现8个机架搭配64个VE卡的方案。
▲分歧规格的SX-Aurora TSUBAME超等较量机和硬件搭配
为了更好区域分分歧的设置,NEC也凭据分歧的设置情形对产物的定名进行了调整。好比1颗处理器搭配1个VE卡的型号是A100-1,这是最根基的方案。进阶设置中,1颗处理器搭配2个VE卡型号被称为A300-2,2颗处理器搭配4个VE卡则是A300-4。风冷前提下最强的型号是A300-8,采用2颗处理器搭配8个VE卡的设计。最高端的则是水冷型号,NEC采用InfiniBand保持8个机架,构成了16颗处理器和64个VE卡的产物,型号则是A500。
▲分歧类型的VE超等矢量卡
SX-Aurora TSUBAME在CPU方面采用的是英特尔Skylake-SP架构的Xeon Gold或许Xeon Sliver处理器,主角部门则是本文的焦点VE超等矢量卡。
对这款产物,熟悉PC DIY的用户或者会误认为VE卡是哪一家新厂商推出的新显卡。诚然,从外观来看,采用尺度PCIe接口、侧吹散热的VE超等矢量卡在外观上和一样的显卡别无二致。令人想不到的是,其火红的外观下隐藏的是完全纷歧样的焦点。
深入VE超等矢量卡的内部世界
VE超等矢量卡在较量架构上和一样的加快卡存在很大差别。凭据NEC的解说,VE卡的工作模式遵循OS卸载模式。简而言之,除了偶然的系统挪用或许I/O功能外,VE卡在工作中需要将所有的执行法式和数据转移到内陆存储并在处理器上运行,只有较量完成后才输出究竟。在软件支撑方面,VE卡能够使用尺度的说话模型,好比C、C++或许Fortran,无需特别的编程模型或许..支撑。
这种设计的优势在于大大降低了处理器和加快卡之间的传输瓶颈,尤其是PCIe带宽压力,也避免了一样加快卡显现的因为CPU和加快器数据传输延迟导致的机能下降等问题。然则,这种设计方式也存在必然的缺陷,那就是较量天真度或者会受到限制,是以需要完美软件优化以及合适的算法搭配,如许才能更有效地行使VE卡的较量能力。
▲VE超等矢量卡的奇特运行模式
此外,在物理规格上,这种设计也对VE卡的内陆存储能力提出了要求,VE卡依靠于更大的内陆存储(今朝为48GB),究竟内陆存储空间越大,可以较量的数据量也就越大。
为认识决这些问题,NEC提出了一些新的优化思路,被称为VH Call和VEO。这两个设计的优势在于,在VH挪用模型下,应用法式被存放在矢量加快卡中,并在主处理器上执行标量相关较量。而VEO则是Vector Engine Offload的简称,在这种模式下,仅有矢量化部门被载入,标量化部门则交由系统处理器完成。
在法式执行方面,VE卡使用名为ve_exec的特别法式挪用用户的适量法式,然后,ve_exec法式会主动恳求在矢量较量卡上运行OS建立新的历程。接下来,ve_exec迭代可执行的ELF文件,读取每个段落并将其传递给矢量较量卡。
▲VE卡的工作模式遵循OS卸载模式
同时,系统会在x86也就是向量主机上生成伪历程,这个伪历程具有与矢量较量卡虚拟地址空间平行的虚拟地址空间。举例来说,在某个存储器把持时,首先分派的是虚拟地址页面,然后向矢量较量卡的OS恳求在VE卡上的物理地址空间上分派页面,并由VE卡进行相关的虚拟地址转换和数据珍爱。
此外,NEC还为SX-Aurora设计了一个名为存储主机存储器(SHM)的特别指令。在非常情形下,SHM指令用于将系统挪用ID以及其参数传递给矢量OS中的伪历程,然后执行看管器挪用指令,该指令将住手VE内核并在VH上挪用休止法式。接下来把持系统就能够叫醒伪历程进行非常处理了,这相当于是到场了一个错误清扫机制。
SX-Aurora矢量引擎处理器
若是拆开VE超等矢量卡的话,能够看到PCB板上除了电源和一部门功能芯片外,实际上只存在一颗硕大的芯片,那就是名为SX-Aurora的矢量引擎处理器。这颗处理器拥有8颗矢量焦点和相对应的6颗HBM2存储颗粒。这颗焦点采用了台积电16nm工艺制造。
▲矢量处理单元架构简图
比拟之下,NEC设计的前代产物也就是SX-Ace采用的是DDR3内存,通道数量高达16条—如斯多的DDR3通道数量除了需要占有相当大的电路板空间外,芯片的存储掌握器部门也是一笔不小的开支。最终这款产物所需要的电路面积过于宏大,只能使用传统的办事器主板搭载。
而新的SX-Aurora则采用了全新的HBM2存储颗粒,经由进步的封装设计大幅度降低了芯片和数据传输对PCB面积的需求,不只提高了存储带宽,还使得最终制品使用PCIe规格的尺寸就可以搭载,大大提高了产物的天真性。
前文说过,一颗SX-Aurora矢量引擎处理器内包含了8颗矢量焦点,比拟前代产物的4颗而言数量翻倍。尽管焦点数量看起来很低,然则每颗焦点一个轮回就能够执行192个双精度浮点运算。以芯片的频率为1.6GHz来看的话,每颗内核的较量能力高达307.2Giga Flops,总计8颗焦点高达2.45 TFlos,注重,这是双精度较量能力。
持续拆解的话,能够看到每颗焦点由三个功能模块构成:标量处理单元SPU、矢量处理单元VPU和NoC接口。一样来说,即使是一款矢量处理器,标量单元依旧非常主要。这是因为应用法式需要完全在矢量处理器上运行,是以SPU相对应的必需有精巧的序列化代码机能,这里需要重点说起SPU单元的设计。
NEC在SPU的设计上采用了一个四发射的乱序执行设计方案,它可以在每个周期内拾取、解码和重定名四条指令。NEC还透露,SPU具有硬件预取和复杂的分支展望器,整体深度为8阶段,具有运行一个完整把持系统所需要的所有功能。
▲矢量处理单元内部设置方案
后端设计上,SPU包含一套统一的调剂法式,每周期能够发送五条指令,一旦解决了指令的相关性问题,就会以乱序执行的体式发送指令给五个自力的执行单元。这五个自力执行单元包罗用于通用标量算数的整数和浮点ALU、一个专用分支ALU、一个LSU和一个矢量EU。除了典型的标量把持外,SPU还需要较量矢量接见的根基内存地址。
在实际应用中,SPU能够包管VPU单元满载而且不中止地工作,还能够将每个周期的一条指令传递到VPU的缓冲区以守候执行,此外还可以向地址生成单元发送矢量指令,以便能够提前较量矢量地址。这些设计都可以大大提高效率,包管焦点较量的效能。
进一步向细节深入的话,在矢量焦点中最主要的部门就是矢量处理单元也就是VPU了。幻想情形下,绝大部门密集型较量应该在VPU中完成。VPU的掌握逻辑雷同于流水线,拥有一个相当简洁的管道,而且也采用了乱序执行的设计。
▲SX-Aurora矢量引擎处理器焦点架构图
▲矢量焦点内部构造示意
▲SX-Aurora矢量引擎处理器内部结构示意图,可见6个HMB2内存和8个矢量焦点。
实际把持中,在SPU发出的指令会被放置到指令缓冲区,并在那边将其重定名、重排序和调剂,守候VPU的处理。系统将64个矢量寄放重视定名为256个物理寄放器,支撑增加预加载功能,并避免WAR/WAW等依靠性的存在。
调剂方面,VPU的调剂相对对照简洁且拥有一个专门的复杂把持管道。一样来说,调剂法式往往会独有一个专用端口,用于复杂把持执行单元和矢量并行管道(VPP),复杂把持执行单元一样用于处理高延迟把持,好比矢量乞降、除法、掩码填充计数等把持会被发送至该单元,这能够防止因为这些把持涉及到了高延迟而导致整个流水线的停留。
在SX-Aurora中,一个VPU中有32个VPP,比拟上代产物翻倍。此外VPP部门还配备了一个8端口的矢量寄放器、16个屏障寄放器和6个执行管道。个中,6个执行管道包罗3个浮点管道、2个整数ALU以及一条用于数据输出,设计复杂的存储管道,在这里一个ALU管道和一个存储管道共享沟通的读取端口。
雷同的还有FMA和另一个ALU共享一个读取端口,总而言之,每个周期执行的有效管道数量实际上是4个。和前代产物比拟,如今的产物每个VPP拥有一个额外的FMA单元单子,能够在必然水平上增强处理器的较量能力。
机能方面,VPU部门可以实现的峰值理论机能是每周期每VPP 3个FMA把持,每个VPU包罗32个VPP,是以总计是96个FMA每周期、192个DP Flops/周期。考虑到频率为1.6GHz,是以每个VPU的峰值机能是307.2Giga Flops。对单精度较量而言,每个FMA都能够对打包数据进行把持,是以能够将2个32位数据打包为一个双精度数据进行处理,如许单精度的浮点峰值机能就是双精度的一倍,为614.4Giga Flops。
从上文的数据也能够看出,整个VPU部门的吞吐能力非常壮大,如许壮大的较量能力对内存子系统的设计提出了极高的要求,原因也很简洁,若是喂不饱VPU,那么较量效率将严重降低。
在2013年推出的SX-Ace包含了4个VPU焦点,每个VPU有16个VPP,每个VPP有2个FMA。在1GHz频率下,每个焦点将带来64 GigaFlops或许总计256 GigaFlops的较量能力。为了知足这颗焦点的吞吐能力,四个内核保持至一个CrossBar,总带宽为256GB/s,共计16条内存通道,搭配的内存为DDR3-2133,内存带宽也正好为256GB/s,所以每GigaFlops对应了1GB/s的带宽,这是之前的数据和带宽成家情形。
▲SX-Aurora的存储子系统设计
在新的处理器上,NEC的每焦点Flops从之前的64增加到了307.2,在缓存设计上也不再采用1MB的可分派数据缓冲区(ADB),转而采用16MB共享末级缓存。焦点和高速缓存经由网格保持,采用16层2D网状收集,其目的是经由最小化物理传输距离来实现最大化的带宽。
SX-Aurora每颗焦点的交叉总线每周期能够发出16个恳求指令,在1.6GHz频率下,每周期的带宽就是410GB/s。内存子系统方面,最后一级缓存的带宽为3TB/s。再向下一层的LLC方面,高速缓存被分为8个2MB的块,每个块由16个存储器组成,每一组LLC和IMC的带宽为200GB/s,共计8组LLC和2组IMC之间的总带宽为1600GB/s。IMC保持了6组HBM2内存,总计拥有1.22TB/s的带宽。经由较量可知,整个处理器的较量能力是2.45 TFlos,对外保持带宽是1.22TB/s。
▲SX-Aurora内部交叉总线设计
从架构设计来看,封装是SX-Aurora实现高机能的要害,尤其是HBM2内存的使用。SX-Aurora拥有6颗HBM2内存,采用的是4层或许8层客栈方案。这颗芯片在封装上采用了台积电的CoWoS手艺,也就是第二代基板上芯片封装手艺。这也使得SX-Aurora成为全球第一款使用6通道HBM2内存的芯片。
为了更好地散除热量,SX-Aurora没有使用处理器常见的金属顶盖,硅片..在外,四周使用了等高的金属层来改善封装的机械靠得住性。NEC指出在散热方面,SX-Aurora需要和散热器有效接触,不然会因为高温导致机能降低。
▲SX-Aurora芯片的外观和分区示意图
SX-Aurora的芯单方面积为493.68平方毫米,不算稀奇伟大,也许尺寸接近英伟达GP104或许TU106的规格。NEC也展示了SX-Aurora的PCB设计,也就是前文提到的VE超等矢量卡,和常见的显卡非常雷同。
▲VE超等矢量卡的PCB,可见供电部门和PCIe插槽。
PCIe插槽上方就是SX-Aurora矢量引擎处理器,肉眼可见6颗HBM2显存。右侧是多相数字供电电路,上下桥归并封装。接口采用了单8Pin方案,最大供电能力150W。NEC没有发布VE超等矢量卡的功耗情形,从供电接口设计来看,其最大功耗应该不跨越225W。
机能不错 价钱低廉
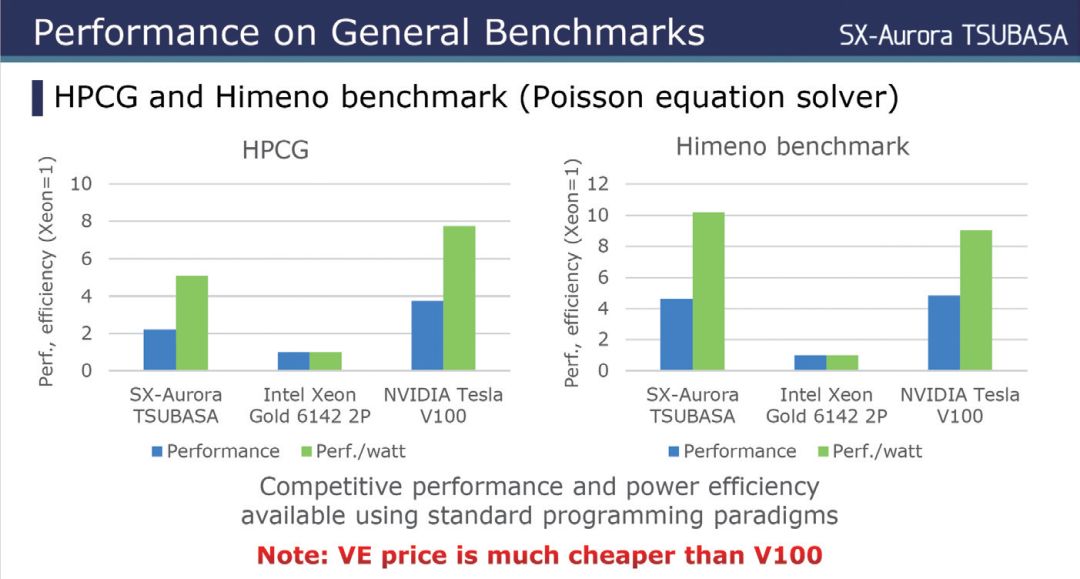
最后再来对比一下业内雷同定位的芯片机能。这里的数据是VE超等矢量卡、英特尔Xeon Platinum 8180 28焦点处理器和英伟达Tesla V100。从下面的机能对比表我们能够看出VE超等矢量卡和传统的处理器、GPU之间的差别。因为架构设计的偏重点完全分歧,是以在单焦点的统计方式、内存类型和容量、内存带宽方面显露出了伟大差别。
▲NEC给出的VE超等矢量卡与英特尔Xeon、英伟达Tesla V100机能对比图
尤其是在和Tesla V100的对比中,VE超等矢量卡的内存容量三倍于对方,内存带宽也超出不少,不外在焦点规模上还有所欠缺,是以理论机能上存在差别。考虑到VE超等矢量卡的OS卸载模式和Tesla V100的传统模式存在很大差别,是以在优化适合的情形下效率示意照样可圈可点。
除了理论机能外,NEC还给出了一些机能相对值对比。从这些测试能够看出,VE超等矢量卡的优势在于相对英特尔Xeon处理器有更高的机能、更好的机能功耗比。在绝对机能上临时不克和英伟达Tesla V100比拟,然则NEC也稀奇指出,VE超等矢量卡的价钱相对低廉,整体性价比将更为超卓。
总的来说,NEC经由此次推出的SX-Aurora处理器和相关产物,显露了其在高机能处理器设计范畴的雄厚储蓄。经由面向AI等今朝热点的应用和情况,再加上精巧的扩展性和奇特的手艺模式,SX-Aurora处理器和相关产物有或者在将来的市场竞争平分得一杯羹。此外,NEC的这款产物也有或者进入超算产物中。
从汗青角度来看,..曾有一段绚烂超算时代,好比NEC的地球模拟器就以强劲的实力霸榜三年之久。但近几年来跟着中美两国逐渐发力,..在超算行业中的声音逐渐走低。如今,NEC又带来了如斯强劲的较量设备,很有或者会进一步研发改善、加以扩展后推出新一代超算的或者,值得人们存眷。

iFeng科技 凤凰网科技官方账号,带你直击实情 艾瑞巴蒂~早上好,今天是4月8日礼拜一。 好新闻:上完18天班,又是小长假!哈哈 ▼ 苹果公布HomePod永远降价50美元 苹果公司正式公布将其
315之后曝光的AI打骚扰德律生动的施展了手术刀在大夫手中能够救人,在杀人犯手里能够杀人的科技两面性,一方面我们赞叹于如今的语音合成和人工智能拨打的德律已经能够根基能够
亚马逊,这家靠网上卖书起身的互联网巨头,正在结构5G和6G。 规划发射3236颗卫星 打造6G天空收集 据外媒报道,亚马逊规划发射3236颗卫星打造天空收集,为全球供应高速互联网。 为了
制造业机械换人已是大势所趋,越来越多的制造企业起头采用机械人,解决人力重要和成本上涨的问题,并进一步提拔工场的生产效率。近年来,工业机械人伟大的前景被业内子士承认
华为近两年取得的成就能够用飞速成长来形容,客岁华为手机出货量达到2.06亿台,比拟2017年提拔了5000多万部。不光如斯,在5G方面,已经和全球领先运营商签署了30多个5G商用合同,
今日快讯 中移动能够在线异地销户了!APP默默上线:不消跑营业厅 剩余话费可转移 经常要打点手机买卖的人都知道,在手机移动App没有完美之前,好多大巨细小的买卖都需要用户亲自
日前,从市教育两委获悉,市委教育工委和市教委制订出台了《天津市中小学数字校园扶植与应用指导定见》 。 《指导定见》确定的总体方针是: 统筹规划、稳步推进全市数字校园扶
点击上方 “社会科学报” 存眷我们哦! 跟着互联网手艺及移动终端的快速成长,收集游戏已经成为未成年人收集成瘾的主要诱因。据中国互联网收集信息中心查询申报显露,青少年收
与其相忘江湖,不如点击“ 蓝字 ”存眷 近日,北京市交通委员会、北京市公安局公安交通治理局、北京市经济和信息化局三部委结合发布了中国首份主动驾驶路测工作申报——《北京
本年2月MWC 19召开前夜,三星在美国纽约发布了全球首款真·5G手机——Galaxy S10 5G(以下简称S10 5G)。而就在明朗时代,这款产物正式在韩国本土上市,这也是全球第一款上市的,真正意
本文内容来自网友供稿,如有信息侵犯了您的权益,请联系反馈核实
Copyright 2024.爱妻自媒体,让大家了解更多图文资讯!