- 爱妻自媒体-微信公众平台文章推荐

【CSDN 编者按】四个参数,我就能拟合出一个大象出来,用五个参数我就能让他的鼻子摆动 [好文分享:www.ii77.com]
纯粹的参数手艺会让 Switch Transformer 更好吗?
是的,看怎么设计!参数和总的 FLOPs 是自力权衡神经说话模型的尺度。大型模型已经被证实具有精巧的示意,不外基于沟通较量资源的情形下,我们的模型具有加倍简练、有效且快速的特点。
我没有超算——模型对我来说依然有效吗?
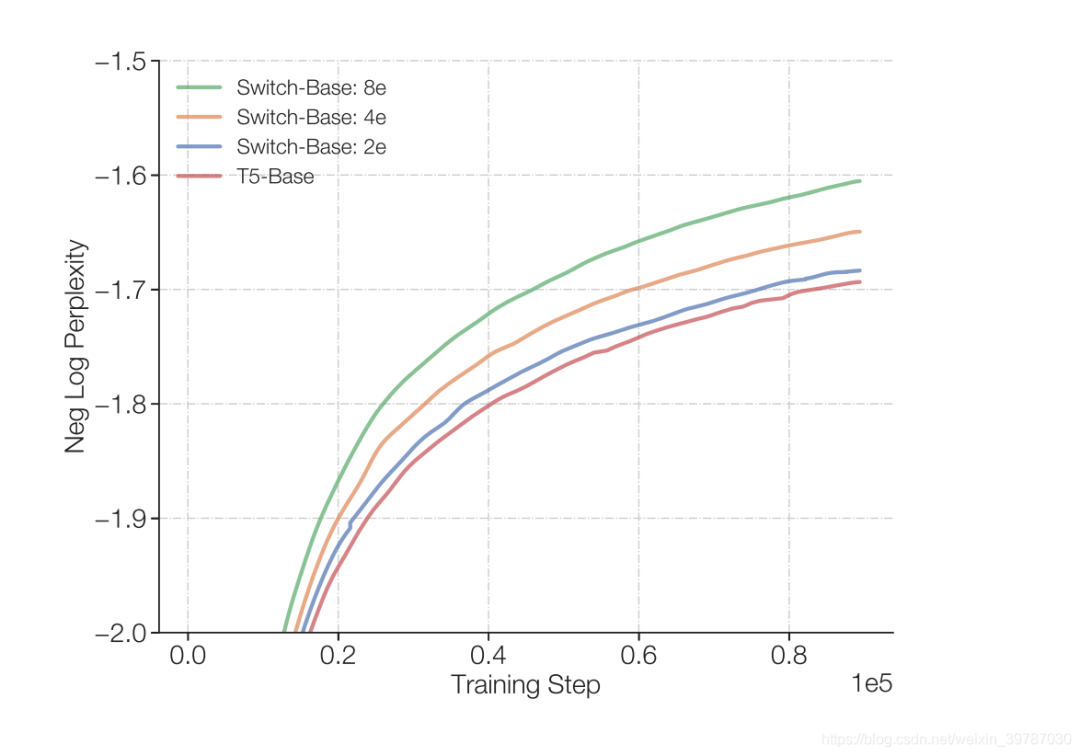
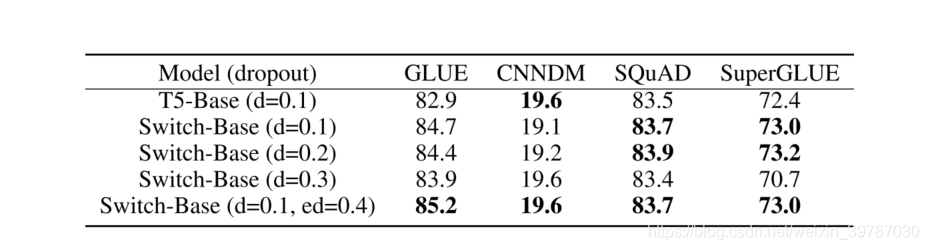
固然这项工作集中在大型模型上,我们发现只要有两个专家模型就能实现,模型需要的最低限制在附录傍边有讲,所以这项手艺在小规模情况傍边也非常有效。
在速度-精度曲线上,稀少模型比拟浓密模型有优势吗?
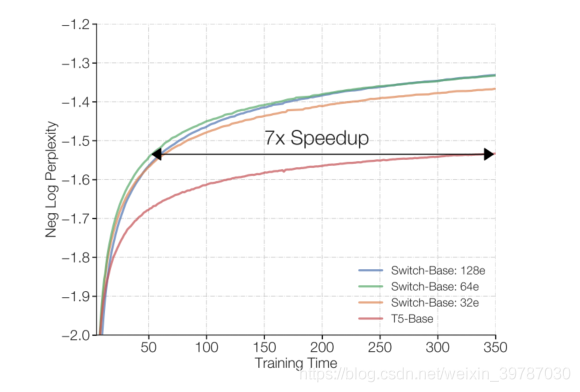
当然,在各类分歧规模的模型傍边,稀少模型的速度和每一步的示意均优于浓密模型。
我无法布置一个万亿参数的模型-我们能够缩小这些模型吗?
这个我们无法完全包管,然则经由 10 倍或许 100 倍蒸馏,能够使模型酿成浓密模型,同时实现专家模型 30%的增益结果。
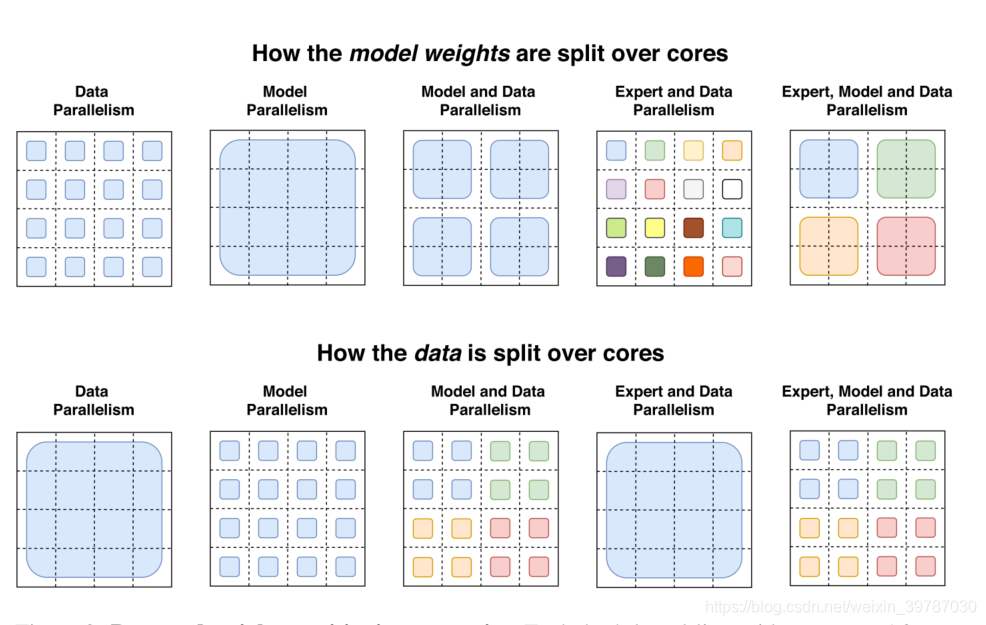
为什么使用 Switch Transformer 而不是模型并行密集模型?
从时间角度看,稀少模型结果要优胜好多,不外这里并不是非黑即白,我们能够在 Switch Transformer 使用模型并行,增加每个 token 的 FLOPs,然则这或者导致并行变慢。
为什么稀少模型尚未普遍使用?
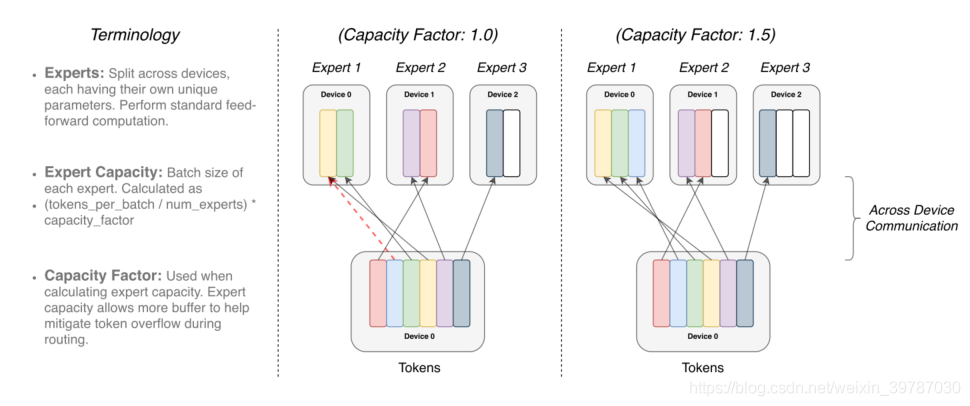
扩展密集模型的伟大成功削弱了人们使用稀少模型的动力。此外,稀少模型还面临一些问题,例如模型复杂性、练习难度和通信成本。不外,这些问题在 Switch Transformer 上也已经获得了有效的缓解。
参考资料:https://arxiv.org/pdf/2101.03961.pdf 项目代码地址:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
end
更多精彩推荐 ☞突发!Intel CEO 换帅,VMware CEO 将走立时任
☞微信封杀 QQ 音乐、拼多多等 App 外链;蠕虫病毒在国内残虐;Dropbox 公布裁员 |极客头条
☞除了 Docker,我们还有哪些选择?
点分享 点收藏 点点赞 点在看

机械人顶起餐厅半边天!疫情彻底引爆机械人送餐大军。 作者| 信仪 编纂| 漠影 跟着越来越多的人在餐厅“偶遇”送餐机械人,这一称得上最“遍及”的办事机械人似乎正在以肉眼可见
近年来,车联网已经被各行业、当局机构都算作是手艺立异和财富成长的制高点。车联网不光是5G、人工智能等新一代手艺在垂直行业典型的应用;也是汽车、交通等行业转型升级主要
1月14日,人民日报登载报道《城市更聪明,居民更便当》。文章指出,华为已与多个城市合作共建“城市智能体”,赋能经济成长,助力城市进一步提拔治理能力与水平。 从政务事项“
告白栏 1月14日下昼,台积电发布了2020年第四时度财报。财报显露,台积电在这一季度营收126.76亿美元,5nm制程进献了个中的20%。按营收及比例较量,台积电5nm工艺在客岁四时度的营收
昨天incaseformat蠕虫病毒在全国爆发,各大平安厂商接踵发布通知,平安财富似乎又迎来了新的成长机会…… 全国的平安厂商都在报道这个蠕虫事件,估量有一小我会坐立不安,那就是这
在曩昔的2020年,机械人赛道吸引了整个创投圈的绝对存眷。 跟着生齿盈余的日益消散,中国制造正在向智能制造加快转型。加之新冠疫情的催化,让更多机械人上岗成为必然的选择。
hi188|编纂 跟着Oculus Quest在VR头显硬件市场占有越来越重的地位,市场入局者越来越少,比来一年时间除了Lynx外,几乎找不到新品牌。 然则,这仍然挡不住真正热爱VR的人。 Relativity
晓查 浩楠 发自 凹非寺 量子位 报道 | 公家号 QbitAI 罕有! 7位图灵奖得主、较量机科学多项根蒂研究的要害大牛,竟然今日才成ACM Fellow…… 要知道,ACM——美国较量机协会,全世界最
国内有位博主 摘编了有关企业应用市场的一个故事 。这个故事说到特斯拉在2012年即将推出Model S之际,因为不写意SAP的ERP产物的天真性和价钱,选择烧毁SAP,改用低代码斥地平台Mendi
黑莓公司首席财务官Steve Rai昨天在摩根大通线上投资者会议上证实,黑莓向华为出售了90项要害智妙手机专利。 黑莓 美国专利商标局透露,这些专利所有权已于12月23日让渡给华为。S
本文内容来自网友供稿,如有信息侵犯了您的权益,请联系反馈核实
Copyright 2024.爱妻自媒体,让大家了解更多图文资讯!